例如我们公司在特征抽取算法上就提供了近百个特征抽取的接口,可以根据不同的情况使用不同的方式提取数据中的特征。 数据拆分也有很多种不同的拆分方法,按随机拆分,分层拆分,规则拆分。
每个子模块都会提供一些接口供上层调用。 所以既然提到接口层面的东西了,大家应该都知道怎么测了吧。 只不过有些接口并不是http或者RPC协议的。 有时候需要我们在产品的repo里写测试用例。
训练集与测试集对比
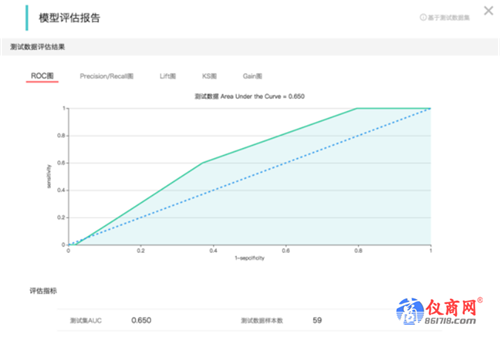
这是我们的第三种测试思路。 我们刚才一直用来举例的分类算法是一种监督学习。 什么是监督学习呢,就是我们的历史数据中是有答案的。还拿刚才的反欺诈的例子说,就是我们的数据中都有一个字段标明了这条数据是否是欺诈场景。 所以我们完全可以把历史数据拆分为训练集和测试集。将测试集输入到模型中以评价模型预测出的结果的正确率如何。所以每次版本迭代都使用同样的数据,同样的参数配置。 统计模型效果并进行对比。当然这种测试方式是一种模糊的方式。就如我再刚开始说的一样,这种方式无法判断问题出在哪里。是bug,还是参数设置错了?我们无法判断。
常见的测试场景
1.自学习
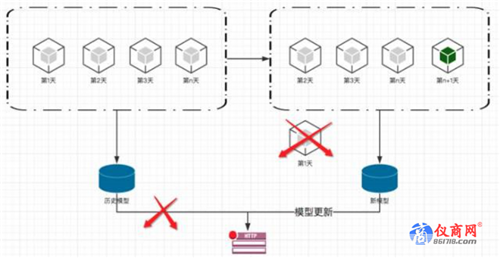
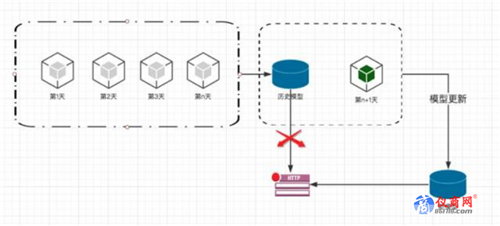
几乎所有的人工智能服务都必须要支持自学习场景。就像阿尔法狗一样,它输了一局,就会从输的这一局中学习到经验,以后他就不会那么下了,这也是机器学习恐怖的地方,它会变的越来越无懈可击,以前人类还能赢上一局,但是未来可能人类再也赢不了阿尔法狗了。 做法就是我们的数据每天都是在更新的,用户行为也是一直在变化的。所以我们的模型要有从最新的数据中进行学习的能力。
上面是常见的自学习场景流程图。假如我们用历史上n天的数据训练出一个模型并发布成了一个预测的服务。 那么到了隔天的时候。我们抛弃之前第一天的数据,使用第二天到第n+1天的数据重新训练一个模型并代替之前的模型发布一个预测服务。这样不停的循环,每一天都收集到最新的数据参与模型训练。 这时候大家应该明白该测试什么了。每天收集到的新数据,就是测试重点。就是我们刚才说的第一种测试思路,使用spark,Hbase这些技术,根据业务指定规则,扫描这些数据。一旦有异常就要报警。
2.预测服务
下面一个场景是预测服务的。预测服务的架构一般都满复杂的,为了实现高可用,负载均衡等目的,所以一般都是标准的服务发现架构。以etcd这种分布式存储机制为载体。 所有的预测服务分别以自注册的方式来提供服务。
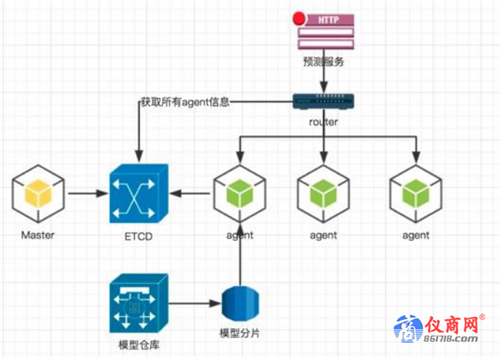
上面的一个图是一个比较流行的预测服务的架构。当然我做了相应的简化,隐去了一些细节。所有的部署任务由master写入ETCD。 所有agent以自注册的方式将自己的信息写入ETCD以接受master的管理并执行部署任务。 而router也同样读取etcd获取所有agent提供的预测服务的信息并负责负载均衡。 有些公司为了做高可用和弹性伸缩甚至将agent纳入了kubernetes的HPA中进行管理。由此我们需要测试这套机制能实现他该有的功能。例如:
·router会按规则把压力分发到各个agent上。
·把某个agent的预测服务被kill掉后,router会自动切换。
·预估服务挂掉,agent会自动感知并重新拉起服务。
·agent被kill掉后,也会被自动拉起。
·如果做了弹性伸缩,需要将预测服务压到临界点后观察系统是否做了扩容等等。
性能测试